
SAP SE released Tuesday its SAP HANA platform that delivers a range of enterprise reliability and data-center scale features, including new hybrid data management service in the cloud, an expanded maintenance strategy and a new offering for small and midsize enterprises (SMEs). This enables companies to embed cloud agility into their on-premise data management environment, provide greater stability for mission-critical workloads and help SMEs go digital with greater ease.
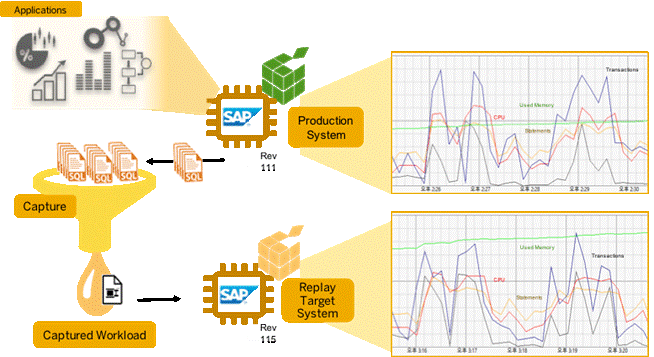
SAP HANA SPS 12 introduces a way to simplify implementing change with the ability to capture workloads and replay them on target systems to simulate real workloads and compare statement runtimes. Target systems can be on different versions of SAP HANA enabling one to replay workloads on a newer version and see how applications will continue to function with changes to the environment, while reducing time and cost when implementing change.
“The SAP HANA platform has successfully become a proven mainstay data management solution, supporting the full range of analytic and transactional software from SAP, both in the data center and in the cloud,” said Carl Olofson, research vice president, Application Development and Deployment, IDC. “The latest release of SAP HANA and expanded maintenance program offer customers innovative features for powerful analytics and smarter, more cost-effective IT system management, and make it an attractive platform for an even wider variety of applications for engaging in the digital transformation of the enterprise. Enhancements like these ease that transformation, where future business growth opportunity is to be found.”
Workload management has the ability to enable/disable workload classes when wanting to lift workload constraints temporarily for specific tasks such as monthly closing. During cross-tenant scenarios (scenarios that access data from more than one tenant in a multi-tenant landscape) workload management settings in all of the tenants are taken into consideration when executing a statement.
In addition to workload management enhancements for multi-tenant landscapes, one can now use system replication for near zero downtime tenant clone/move, turn on audit logging for cross-tenant scenarios, and have access to more granular information for monitoring purposes.
Additionally, system replication in SAP HANA SPS12 adds more sync/async combinations between first, second, and third replication tiers for greater flexibility when managing system landscapes. With this capability, it becomes easier to rotate the roles of servers. This release also extends the choices for the system replication initial data loads. When network throughput environments are suboptimal. one can now create the initial data load from backup snapshot files.
Modern IT is seeking to leverage unique business applications to boost competitive advantage. In SAP HANA SPS 11, the company re-architected the application services to scale independently from database services and supported new runtimes: JavaScript(Node.js), and Java on Apache TomEE/Tomcat.
With SPS12, support for standard code management tools, such as Git, GitHub and Maven, expands to include integrated Git/Gerrit for improved workflow of Git approvals and code reviews. To improve the performance, SAP HANA SPS 12 debuts the concept of partial runtime download, which allows us to avoid redeploying an entire Java or Node.js runtime upon each service startup.
Usually businesses have huge volumes of text data that contain hidden insights. To gain more value from text data. text mining in SAP HANA SPS12 features two major enhancements. First, the previously inaccessible text mining index is now available for data scientists as a system table that can be used as the basis for custom/proprietary algorithms. The text mining index is a data structure that describes the frequency of terms that occur in a collection of reference documents, which is built from the results of text analysis during pre-processing. Second, text mining features improved precision by leveraging multi-word concepts (i.e. ‘fast food’ or ‘retirement home’) identified by text analysis in 32 languages. These concepts extend the definition of terms that are used by text mining, yielding higher precision.
In the area of spatial processing, the Application Function Library (AFL) SDK now supports spatial data types, which allows building custom spatial algorithms. Spatial operations depend on reference systems, e.g. planar Euclidian space or a round earth. SPS12 now supports automatic import of common reference systems (i.e. SRS and UOM) which simplifies configuration.
Moreover, geocoding (i.e. address to latitude/longitude) is now natively available in SAP HANA as part of smart data quality. Finally, integration with 3rd party geospatial tools such as GeoTools (geoserver, uDig, e.t.c.), ESRI ArcGIS, and Hexagon Geo-spatial, are now supported to drive continued openness.
SAP HANA graph data processing is now generally available, providing the processing capabilities help customers extract deeper insights from hyper-connected data and their relationships. SAP HANA includes a graph engine with built-in graph algorithms (neighborhood search, shortest path, strongly connected components, pattern matching) to find connections without manually creating complex JOIN statements.
It also introduces a Property Graph model with flexible schema, which enables users to traverse relationships without the need for predefined modeling, and comes with a graph viewer tool (for quick visualization and dynamic interaction (i.e. change algorithm parameters) with graph data real-time, and a graph modeler tool that is (integrated with SAP Web IDE for SAP HANA to create and consume graphs visually instead of via SQL or SQLScript.
From a tooling perspective, the SAP Web IDE for SAP HANA has added cross-object impact analysis (to identify the impact of a change in a lower-layer source object and evaluate the impact of that change on referenced object) and lineage analysis (to follow the source path of data up to the object of interest). Both the SAP Web IDE for SAP HANA and SAP PowerDesigner now supports core data services (CDS) artifacts.
SAP HANA smart data Integration (SDI) continues enhancing adapters to handle more scenarios. It now supports new sources such as: Google+, Informix, E-mail (.pst) file. These new adapters allow customers to access data from a broader range of of systems.
Moreover, the adapters for OData and Hadoop HDFS (.csv) have been enhanced so support read/write scenarios. Beyond adapter enhancements, SAP HANA smart data integration also enhanced new operational capabilities, such as scheduling or starting tasks immediately, processing remote subscription exceptions and creating, altering and dropping agents. Its ability to start, pause, resume and stop real time replication is also critical.
SAP HANA smart data integration also supports data masking during ETL processes, which obfuscates and masks personally identifiable information while retaining data relationships and relevancy. It helps customers comply with data privacy and protection policies.


